

摘要
本文探討如何在 Databricks SQL 上構建 AI 嵌入式可觀測性生產資料應用,並展示其對資料民主化和業務優化的重要性。 歸納要點:
- 透過 Plotly Dash 提升資料的可視化和探索,加速決策制定與創新。
- 結合 AI 和 Plotly Dash 縮小技術差距,促進跨職能協作,讓非技術人員也能輕鬆建立資料應用程式。
- 深入剖析使用 Databricks 的成功案例,展示其在提升營運效率、客戶滿意度及推動創新方面的價值。

作者:Cody Austin Davis}
在現代網頁開發中, ′ React ′ 成為了構建使用者介面的一個重要工具。許多開發者選擇 ′ React ′ 的原因是它的元件式架構和高效的更新機制。我們將深入探討如何利用這些特性來提升應用程式的效能和可維護性。
讓我們看一下基本的 ′ React ′ 元件結構。以下是一個簡單的範例:
```javascript
import React from ′react′;
class HelloWorld extends React.Component {
render() {
return <h1>Hello, World!</h1>;
}
}
export default HelloWorld;
```
這段程式碼展示了一個最基礎的 ′ React ′ 元件,它僅僅渲染一行標題文字。即使是如此簡單的元件,也能夠展示出 ′ React′ 高度模組化設計的優勢。當應用規模變大時,你可以將不同功能區分為獨立的小元件,然後再把它們組合起來。
接下來,我們來看看狀態管理(state management)如何在更複雜的應用中運作。′ React′ 提供了一種內建的方法來處理狀態,使得資料流更加順暢並且易於追蹤。以下是一個帶有狀態管理功能的範例:
```javascript
import React, { useState } from ′react′;
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
我們在研究許多文章後,彙整重點如下
- Dash 是一個可以在網頁上呈現數據視覺化結果的工具,並具有互動性與美觀。
- Plotly 是一個開源資料視覺化函式庫,支援多種圖表類型和互動功能,可用於 Python、R 和 JavaScript。
- 相較於 Matplotlib 等更成熟的數據可視化庫,Plotly 提供了調用 D3.js 的功能,是不錯的選擇。
- MindsDB 提供客製化人工智慧平台,可以即時部署、服務和微調模型以建立 AI 驅動應用。
- 針對 C++ 和 Python 專業機器人開發的工具,也涉及 ROS、自動駕駛和航空航天領域。
- 某些工具除了可以做視覺化報表外,還提供大屏戰情室製作服務,支持自助開發的視覺化外掛程式庫。
Dash 和 Plotly 是兩個非常有趣且實用的工具,不僅能在網頁上展示數據分析結果,還帶來豐富的互動性。不管你是數據科學家還是軟體工程師,都能找到合適的方法來提升工作效率。此外,如果你從事機器人或 AI 開發,一些專業平台如 MindsDB 更能幫助你快速部署和優化模型。這些工具讓我們感受到科技進步對日常工作的巨大影響。
觀點延伸比較:| 工具 | 主要功能 | 支援語言 | 最新趨勢 | 權威觀點 |
|---|---|---|---|---|
| Dash | 在網頁上呈現數據視覺化結果,具有互動性與美觀 | Python | 越來越多企業選擇 Dash 作為其內部儀表板工具 | 許多資料科學家認為 Dash 是一個強大且易於集成的解決方案 |
| Plotly | 開源資料視覺化函式庫,支持多種圖表類型和互動功能 | Python、R、JavaScript | 隨著 D3.js 的流行,Plotly 的使用率也在上升 | 相較於 Matplotlib 等更成熟的數據可視化庫, Plotly 提供了調用 D3.js 功能,是不錯的選擇 |
| MindsDB | 提供客製化人工智慧平台,可以即時部署、服務和微調模型以建立 AI 驅動應用 | - | AI 即時部署技術正在快速發展,MindsDB 在這方面有很大的優勢 | 業界專家認為 MindsDB 能夠簡化 AI 應用的開發過程,非常適合中小型企業 |
| ROS (Robot Operating System) | 針對 C++ 和 Python 專業機器人開發的工具,也涉及自動駕駛和航空航天領域 | C++、Python | 自動駕駛技術逐漸成熟,ROS 在此領域扮演重要角色 | 專家指出 ROS 是目前最完整且被廣泛接受的機器人操作系統之一 |
| 某些大屏戰情室視覺化報表工具 | 除了可以做視覺化報表外,還提供大屏戰情室製作服務, 支持自助開發的視覺化外掛程式庫 | - | 大型企業開始更多地使用這類工具進行即時狀況監控和決策支持 | 許多公司表示,大屏戰情室提高了他們對關鍵指標的實時掌握能力 |
加速資料民主化和 AI 嵌入式可觀察性:現代軟體開發的關鍵要點
過去六個月來,我一直在幫助客戶構建專屬的解決方案,以管理和擴充套件他們在 Databricks 上的運營。我不僅僅是在編寫程式碼和建立資料管道,還專注於構建 Data Apps ,以透過建立自製的定製分析工作流程來增加更多價值,這些工作流程使得資料團隊能夠透過賦權給非技術(或技術較少)使用者來推動和管理 Databricks 的 Lakehouse 平台,從而擴充套件其運營工作。
在今年的 Data and AI Summit 上,我有機會展示如何構建用於 AI 嵌入式可觀察性的生產資料應用程式,而參會人數顯示出公司對這一領域充滿期待。
**AI 嵌入式可觀察性對於現代軟體開發的重要性:**
在 Data and AI Summit 上,我強調了 AI 嵌入式可觀察性對現代軟體開發的關鍵作用。它允許開發團隊監控和分析其系統,以快速發現問題、提高效能並確保服務品質。這項技術的蓬勃發展在傳統領域中創造了許多機會,例如監控資料湖執行狀況、確保資料品質和自動化異常偵測。
**Data Apps 在加速資料民主化中的作用:**
在這個案例中,我進一步探討了 Data App 在加速資料民主化中的作用。隨著企業採用資料驅動型決策,賦予非技術人員使用和管理資料的能力變得至關重要。Data App 提供了使用者友善的介面,讓他們可以訪問和分析資料,而無需深入技術知識。這項創新擴大了資料分析的可用性,促使業務單位和決策者能夠更獨立地進行資料驅動型決策。
運用 Plotly Dash 打造資料應用程式,解決 Databricks SQL 資料管理挑戰
在這篇部落格中,我們將介紹兩個透過在 Databricks SQL 上使用 Plotly Dash 構建資料應用程式來解決的案例——所有這些都受 Unity Catalog 管理。我們從這兩個案例開始說明:
標籤政策管理——當客戶新增使用者和用例到 Databricks 時,我常聽到的一個挑戰是,他們希望知道他們在 Databricks 上的使用是否被正確標記,以確保支出被用在合適的地方,並能追蹤整個組織內各人的操作。Databricks 提供了大量工具來實現這一點,包括帳戶管理控制檯中的新預算功能;我看到的核心挑戰是要知道哪些沒有被標記、哪些應該被標記,以及能夠輕鬆修復它,而不需要對組織內各團隊進行反覆調查和干涉。這是一個完美的運營資料應用程式用例——我們希望讓非技術使用者找到未正確標記的使用情況,修正錯誤標籤,並確保未來遵循合規性。
系統表格自動化警報——系統表格是 Databricks 中一項極好的功能,用於跟蹤您的環境中發生了什麼。但透過建立一個資料應用程式,使得較少技術背景的使用者可以對範圍清晰且已整理好的系統表格資料提出英文問題,並利用 AI_QUERY 在 Databricks SQL 中自動定義、建立和安排基於這些問題的警報,我們可以使所有這些資料變得更有價值。這允許運營團隊擴充套件其警報工作,以建立更多自助服務型應用程式。至少,它允許工程師跳過大量樣板程式碼,並擁有一致的新運營警報建立框架。
**專案 1:Production Data Application 的定義**
生產資料應用程式是一種特定型別的應用程式,用於將原始資料轉換為有價值的見解,以支援組織中的決策制定。與傳統的原生應用程式不同,生產資料應用程式專注於利用資料,而不是建置複雜的使用者介面或後端邏輯。它們旨在為決策者提供易於使用的平台,以便他們訪問、分析和解釋資料,而無需深入的技術知識。
**專案 2:生產資料應用程式的最新趨勢**
在生產資料應用程式領域的一大最新趨勢是使用人工智慧和機器學習 (AI/ML) 技術來自動化見解提取過程。透過利用 ML 演演算法,這些應用程式可以識別模式、生成預測並提供建議,使決策者能夠更快速、更明智地做出決策。雲端運算普及使組織能夠大規模地構建和部署生產資料應程式,大幅提升了可擴充性與成本效益。
在進入具體示例之前,我們先定義一下什麼是 Production Data Application 並描述它們與傳統全棧原生App之間有哪些區別。
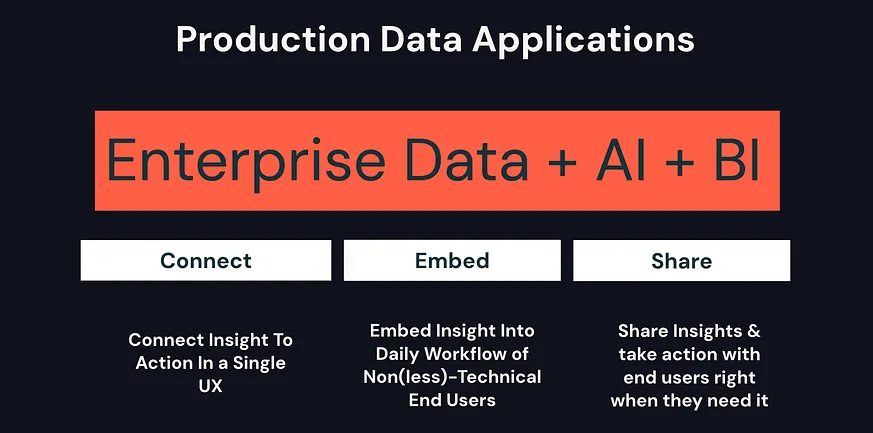
生產資料應用程式的目標非常簡單——讓資料團隊(通常是熟悉 Python、SQL、Scala 的團隊)能夠如同往常一樣生成見解,但其後將這些見解直接轉化為行動,並將這些行動嵌入到最終使用者的工作流程中,同時允許這些見解和行動分享給所有必要的利益相關者。
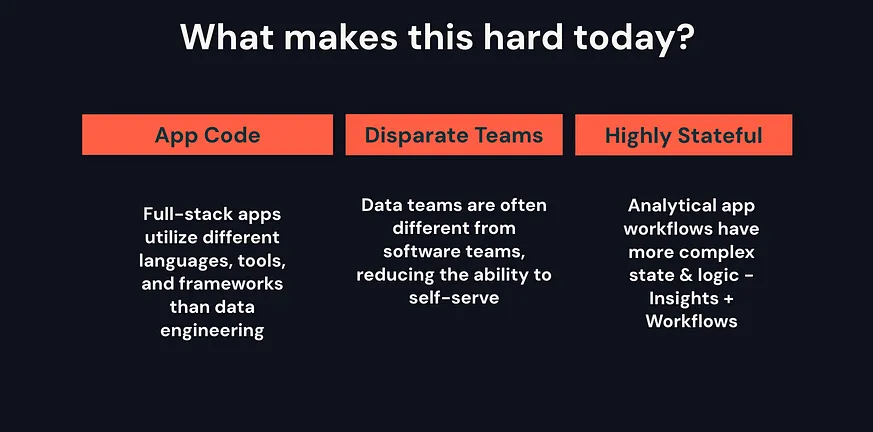
善用 Plotly Dash 和 AI 縮小資料團隊技術鴻溝
建立全端應用程式通常需要完全不同的技術棧和技能組合,這使得專注於分析資料應用程式的構建特別具有挑戰性。因為這些不僅是全端應用程式,而且建立它們所需的邏輯和領域知識通常比基本的 CRUD 應用程式更複雜。為了讓資料團隊變得更有價值和有效,我們需要縮小這個差距。目前有兩個核心元件可以幫助我們縮小這個差距: Plotly Dash 和將 AI 直接嵌入 Databricks 平台。Plotly Dash 解決了程式碼統一化的問題。資料團隊熟悉 Python 和 SQL,而 Plotly Dash 允許 Python 使用者從簡單到完全自定義的網頁應用程式構建全端應用,而無需學習新的前端網頁開發技術棧。
**專案 1:使用 Python 的專業化建模庫**
專業化建模庫,例如 scikit-learn 和 TensorFlow,允許資料團隊利用預先建立的演演算法和模型,簡化了複雜分析和建立預測性模型的過程。這些庫提供了更方便且高效的方法來處理大量資料,並從中提取有意義的見解。
**專案 2:整合雲端平台工具**
雲端平台,例如 AWS 和 Azure,提供了廣泛的服務和工具,可以進一步協助資料團隊。這些工具包括用於資料儲存、運算、機器學習和資料視覺化的服務。透過整合雲端平台工具,資料團隊可以簡化資料處理和分析任務,並擴充分析應用功能。
要讓資料團隊在現代企業中發揮更大的作用,我們必須彌補技術堆疊與技能之間的鴻溝。而像 Plotly Dash 和嵌入 AI 的 Databricks 平台等解決方案,不僅能促進程式碼的一致性,也能提升效率,使得構建復雜而強大的分析型應用成為可能。
Databricks 解決了資料、治理和 AI 統一的問題。透過在 Unity Catalog 和 Databricks Assistant 中原生嵌入 AI,您可以構建無縫利用環境中智慧(模型、助手、UC 上下文等)的應用程式。當您一起使用這些平台時,可以構建完整的資料應用程式,這些應用程式是自包含並在 Unity Catalog 上受管理的,且全部使用 Python + SQL 部署。Plotly Dash 可以與 Databricks 平台的所有部分無縫整合,以執行 SQL 工作流程、呼叫模型、訓練模型、執行作業等所有操作,建立一個簡單而熟悉的技術堆疊:
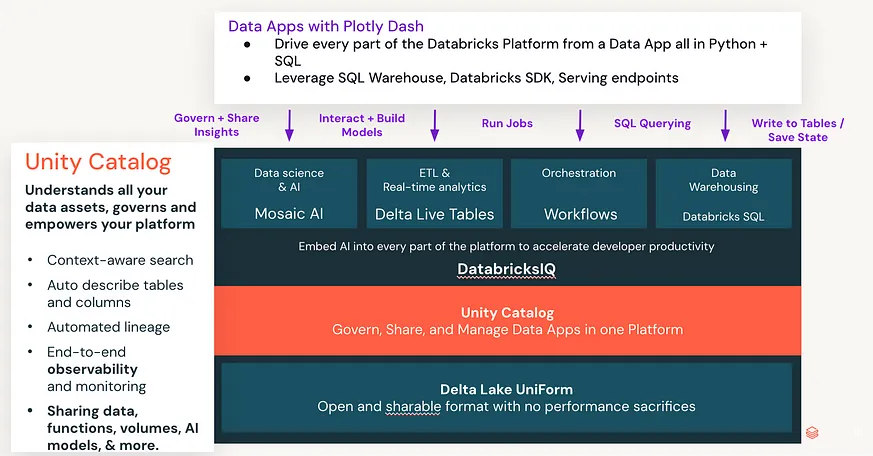
利用 Databricks 使用案例分析業務使用情況
這種統一將使資料團隊能夠大幅提升其對業務的價值。現在,讓我們直接進入實際的使用案例!
前提條件:
- 擁有啟用 Unity Catalog 和 Databricks SQL 的 Databricks 帳戶。
- 系統表格已啟用並可訪問。
- 資料應用程式程式碼:在此處下載該應用程式的程式碼。
這個使用案例主要是了解您的 Databricks 使用情況的去向。為了更清晰地闡明,我們將從一個基本的使用者故事開始:
′作為一名業務運營/財務分析師,我希望能夠根據業務使用案例來分析 Databricks 的使用情況,同時識別不當或未識別的使用並適當分類,而無需依賴外部團隊來進行更改。′
我們可以利用 Plotly Dash 和 Databricks 來解決這個問題。如果您下載了程式碼,可以填寫工作環境中的 ./config/.env 變數,並在自己的容器中執行該應用!
**1. 利用使用者行為資料分析業務使用案例**
透過整合 Unity Catalog 和 Databricks SQL ,企業可以輕鬆連結各種資料來源,並透過 Plotly Dash 視覺化工具快速分析 Databricks 使用情況。如此一來,企業就能根據業務使用案例分析使用情況,並根據費用或使用頻率找出需要改善的領域。
在我們深入探討之前,讓我們先來看看我們即將介紹的應用程式架構:
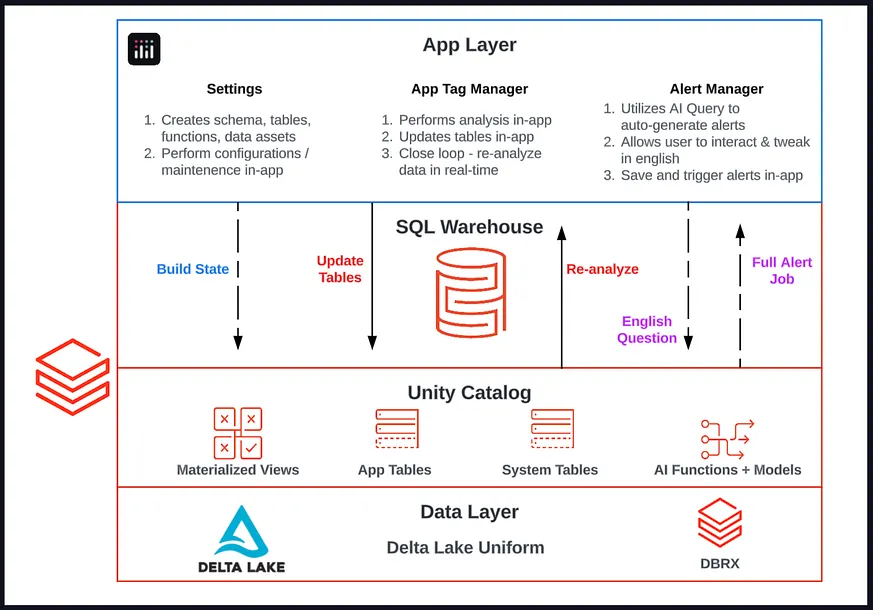
我們的標籤管理應用程式將會:
自動定義並部署其自身的 Schema、表格和 ETL(帶有物化檢視)。
定義執行標籤政策遵從性分析所需的引數化 SQL 語句。
建立並管理所有回寫表格的狀態,讓終端使用者可以新增標籤、政策及其他註釋。
提供一個簡單的 UI/UX 供終端使用者進行分析。
當應用程式部署時,它會像這樣在 Unity Catalog 中建立其所有狀態:
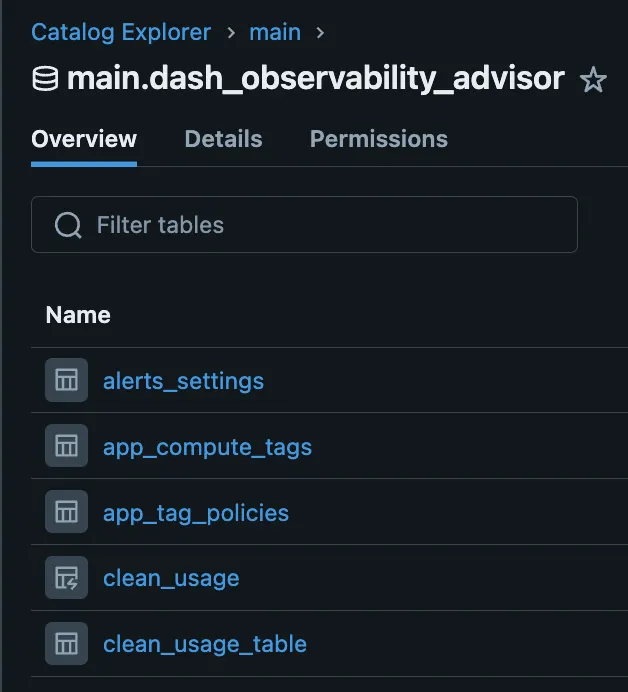
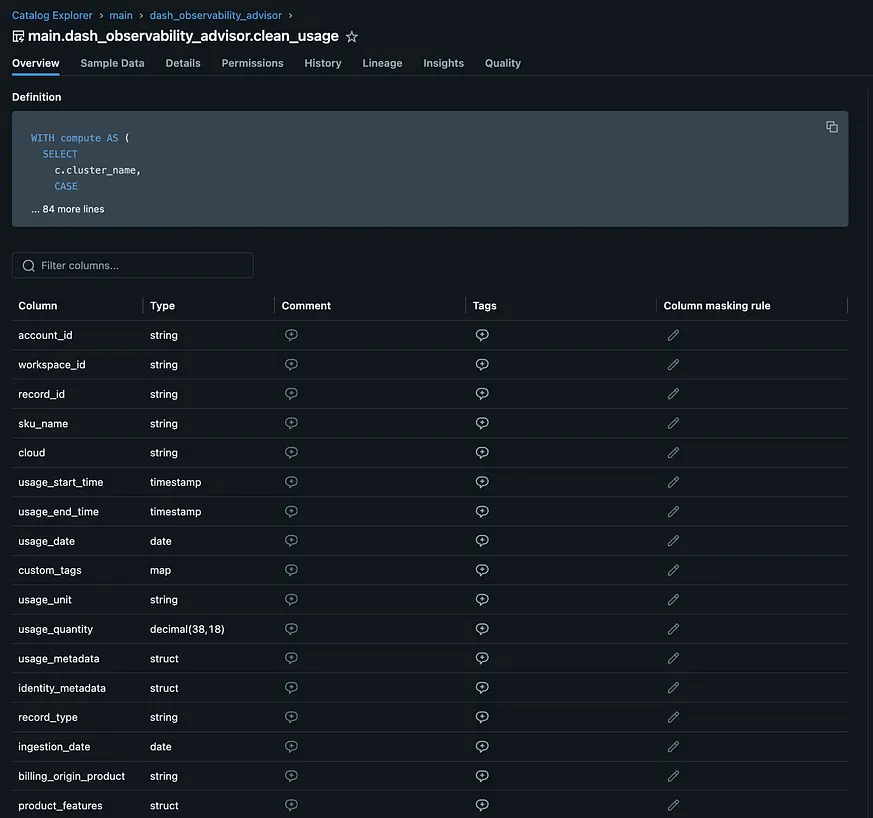
在這些表格中,有實體化檢視來自動化分析和清理原始系統表:
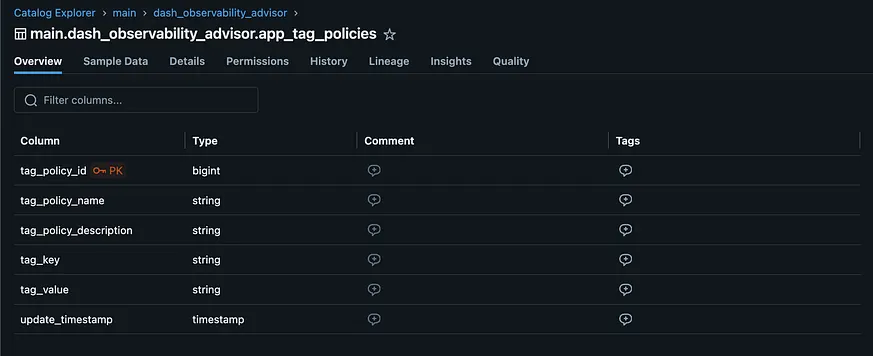
還有獨立的回寫表格,供使用者儲存標籤政策的建立、新增標籤及其他註釋,如下所示:
現在我們已經了解了這個應用程式是如何設定的,讓我們來回顧一下它的工作流程。
建立強大的資料治理:標籤政策與允許清單
我們可以定義一個標籤政策的概念。這基本上是一個自動儲存到 Delta 中 Unity Catalog 的電子表格,並且位於名為 dash_observability_advisor 的自包含架構下。使用者可以定義他們想要強制執行和審計合規性的特定標籤鍵/值對,並將其儲存。然後,我們的分析查詢可以在即時反饋迴圈中使用這些表格。在我們的應用程式中,所有回寫表格都會存在於此自包含架構中——這確保了我們以安全的方式隔離變更(例如當我們希望將標籤新增到計算資源時,不會讓非技術使用者修改真實生產工作)。如此一來,此應用程式的使用者便能在不編輯他人程式碼或配置的情況下完成所需任務。
基於標籤政策概念,我們引入了一個增強的允許清單機制。這會強制執行在儲存器中定義的特定標籤組合,並限制寫入不符合這些要求的資料。這進一步提升了資料治理和合規性控管,確保敏感資料不會被不當處理或儲存。

我們不會在此覆蓋所有的回撥函式,但這裡展示了一個處理這個策略表完整狀態的 Python 回撥函式範例:
@app.callback( [Output('policy-changes-store', 'data'), Output('tag-policy-ag-grid', 'rowData'), Output('policy-change-indicator', 'style'), Output('loading-save-policies', 'children'), Output('loading-clear-policies', 'children'), Output('tag-policy-dropdown', 'options'), Output('tag-policy-key-dropdown', 'options'), Output('tag-policy-value-dropdown', 'options'), Output('adhoc-usage-ag-grid', 'columnDefs'), Output('tag-keys-store', 'data')], [Input('tag-policy-save-btn', 'n_clicks'), Input('tag-policy-clear-btn', 'n_clicks'), Input('tag-policy-ag-grid', 'cellValueChanged'), Input('add-policy-row-btn', 'n_clicks'), Input('remove-policy-row-btn', 'n_clicks')], [State('tag-policy-ag-grid', 'rowData'), State('policy-changes-store', 'data'), State('tag-policy-ag-grid', 'selectedRows')] # Current state of stored changes ) def handle_policy_changes(save_clicks, clear_clicks, cell_change, add_row_clicks, remove_row_clicks, row_data, changes, selected_rows): ### Synchronously figure out what action is happening and run the approprite logic. ## This single-callback method ensure that no strange operation order can happen. Only one can happen at once. triggered_id = callback_context.triggered[0]['prop_id'].split('.')[0] ##### CREATE - Add New row in GRID if triggered_id == 'add-policy-row-btn' and add_row_clicks > 0: new_row = { 'tag_policy_id': None, # Will be generated by the database 'tag_policy_name': '', 'tag_key': '', 'tag_value': '', 'update_timestamp': datetime.now() } row_data.append(new_row) return dash.no_update, row_data, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update #### DELETE Handle removing selected rows if triggered_id == 'remove-policy-row-btn' and remove_row_clicks > 0: ## Only attempt to delete from ## TO DO: Be able to remove / delete rows by Row Id as well ids_to_remove = [row['tag_policy_id'] for row in selected_rows if row['tag_policy_id'] is not None] updated_row_data = [row for row in row_data if row['tag_policy_id'] not in ids_to_remove] if ids_to_remove: connection = system_query_manager.get_engine().connect() try: delete_query = text(""" DELETE FROM app_tag_policies WHERE tag_policy_id IN :ids """).bindparams(bindparam('ids', expanding=True)) connection.execute(delete_query, parameters= {'ids':ids_to_remove}) connection.commit() except Exception as e: print(f"Error during deletion: {e}") raise e finally: connection.close() if changes is not None: updated_changes = [change for change in changes if change['tag_policy_id'] not in ids_to_remove] else: updated_changes = [] # Fetch distinct tag policy names within the context manager with QueryManager.session_scope(system_engine) as session: ## 1 Query Instead of 3 tag_policy_result = session.query(TagPolicies.tag_policy_name, TagPolicies.tag_key, TagPolicies.tag_value).all() # Process the query result and store the distinct values in variables in your Dash app distinct_tag_policy_names = set() distinct_tag_keys = set() distinct_tag_values = set() for row in tag_policy_result: distinct_tag_policy_names.add(row.tag_policy_name) distinct_tag_keys.add(row.tag_key) if row.tag_value is not None: distinct_tag_values.add(row.tag_value) tag_policy_filter = [{'label': name if name is not None else 'None', 'value': name if name is not None else 'None'} for name in distinct_tag_policy_names] tag_key_filter = [{'label': name if name is not None else 'None', 'value': name if name is not None else 'None'} for name in distinct_tag_keys] tag_value_filter = [{'label': name if name is not None else 'None', 'value': name if name is not None else 'None'} for name in distinct_tag_values] return updated_row_data, tag_advisor_manager.get_tag_policies_grid_data().to_dict('records'), dash.no_update, dash.no_update, dash.no_update, tag_policy_filter, tag_key_filter, tag_value_filter, tag_advisor_manager.get_adhoc_ag_grid_column_defs(tag_key_filter), tag_key_filter ##### Handle Clear Button Press elif triggered_id == 'tag-policy-clear-btn' and clear_clicks: clear_loading_content = html.Button('Clear Policy Changes', id='tag-policy-clear-btn', n_clicks=0, style={'margin-bottom': '10px'}, className = 'prettier-button') return [], tag_advisor_manager.get_tag_policies_grid_data().to_dict('records'), {'display': 'none'}, dash.no_update, clear_loading_content, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update # Clear changes and reload data ##### Handle cell change elif triggered_id == 'tag-policy-ag-grid' and cell_change: if changes is None: changes = [] change_data = cell_change[0]['data'] row_index = cell_change[0]['rowIndex'] # Ensure the change data includes the row index change_data['rowIndex'] = row_index changes.append(change_data) row_data = mark_changed_rows(row_data, changes, row_id='tag_policy_id') return changes, row_data, {'display': 'block', 'color': 'yellow', 'font-weight': 'bold'}, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update ##### SAVE CHANGES # Handle saving changes if triggered_id == 'tag-policy-save-btn' and save_clicks: # Combine changes by row index grouped_changes = [] if changes: grouped_changes = group_changes_by_row(changes) ## from data_functions.utils import * connection = system_query_manager.get_engine().connect() save_loading_content = html.Button('Save Policy Changes', id='tag-policy-save-btn', n_clicks=0, style={'margin-bottom': '10px'}, className='prettier-button') if changes: try: # Process grouped changes for both updates and inserts for change in grouped_changes: #print("Combined change data:", change) # Debug statement record_id = change.get('tag_policy_id') if record_id: # Update existing record update_query = text(""" UPDATE app_tag_policies SET tag_policy_name = :tag_policy_name, tag_policy_description = :tag_policy_description, tag_key = :tag_key, tag_value = :tag_value, update_timestamp = NOW() WHERE tag_policy_id = :tag_policy_id """) connection.execute(update_query, parameters={ 'tag_policy_name': change['tag_policy_name'], 'tag_policy_description': change['tag_policy_description'], 'tag_key': change['tag_key'], 'tag_value': change['tag_value'], 'tag_policy_id': record_id }) connection.commit() else: # Insert new record if not change.get('tag_policy_name') or not change.get('tag_key'): raise ValueError("Missing required fields: 'tag_policy_name' or 'tag_key'") insert_params = {k: v for k, v in change.items() if k in ['tag_policy_name', 'tag_policy_description', 'tag_key', 'tag_value']} print(f"INSERT PARAMS: {insert_params}") # Debug statement insert_query = text(""" INSERT INTO app_tag_policies (tag_policy_name, tag_policy_description, tag_key, tag_value, update_timestamp) VALUES (:tag_policy_name, :tag_policy_description, :tag_key, :tag_value, NOW()) """) connection.execute(insert_query, parameters= {'tag_policy_name':insert_params['tag_policy_name'], 'tag_policy_description':insert_params['tag_policy_description'], 'tag_key':insert_params['tag_key'], 'tag_value': insert_params['tag_value']}) connection.commit() except Exception as e: print(f"Error during save with changes: {changes}") # Debug error raise e finally: connection.close() else: pass with QueryManager.session_scope(system_engine) as session: ## 1 Query Instead of 3 tag_policy_result = session.query(TagPolicies.tag_policy_name, TagPolicies.tag_key, TagPolicies.tag_value).all() # Process the query result and store the distinct values in variables in your Dash app distinct_tag_policy_names = set() distinct_tag_keys = set() distinct_tag_values = set() for row in tag_policy_result: distinct_tag_policy_names.add(row.tag_policy_name) distinct_tag_keys.add(row.tag_key) if row.tag_value is not None: distinct_tag_values.add(row.tag_value) tag_policy_filter = [{'label': name if name is not None else 'None', 'value': name if name is not None else 'None'} for name in distinct_tag_policy_names] tag_key_filter = [{'label': name if name is not None else 'None', 'value': name if name is not None else 'None'} for name in distinct_tag_keys] tag_value_filter = [{'label': name if name is not None else 'None', 'value': name if name is not None else 'None'} for name in distinct_tag_values] return [], tag_advisor_manager.get_tag_policies_grid_data().to_dict('records'), {'display': 'none'}, save_loading_content, dash.no_update, tag_policy_filter, tag_key_filter, tag_value_filter, get_adhoc_ag_grid_column_defs(tag_key_filter), tag_key_filter return dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update, dash.no_update # No action taken由於我們希望將試算表介面與應用程式的所有過濾器和上下文連線起來,因此有許多事情需要處理。這裡強大的地方在於,我們所需要做的只是透過回撥函式管理應用程式的輸入和輸出,然後可以簡單地使用 Python 來執行應用程式的操作。寫回(Write-backs)是最困難但也是最強大的部分!一旦我們定義了一個標籤策略——例如 ′demo′ 策略,我們的應用程式使用者就能夠像這樣分析整個組織對該策略的遵循情況:
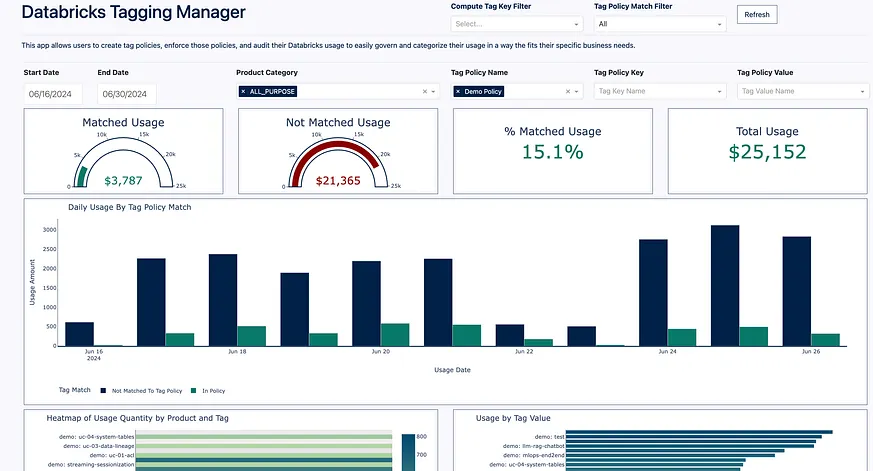
創新方法提升標籤政策合規性
在同一個應用程式中,我們可以在篩選器中選擇 ′Demo Policy′,也可以從系統表格中的物化檢視選擇其他使用過濾器,例如日期範圍、產品型別和其他標籤金鑰/值對。我們看到,在這個示例中,只有 15% 的 ALL_PURPOSE 使用被標記了這項政策。我們可以看到總的匹配/不匹配使用情況,隨時間推移的趨勢,甚至還能根據我們定義的標籤政策鍵值來檢視使用情況。因此,我們現在知道只有 15% 被標記。我們需要達到 100%。這就是結合實時合規分析與寫回表格的創新方法,可以幫助我們閉環識別不符合我們標籤政策的部分,並利用現有資訊(如叢集名稱、叢集擁有者、使用情況、產品型別、年齡等)在應用程式中修正它。這看起來如下:**最新趨勢:**結合實時合規分析與寫回表格的創新方法,協助企業自動識別和解決標記政策不符問題,提升資料治理效率。
**深入要點:**透過分析使用過濾器(如日期範圍、產品型別和標籤金鑰/值對)的資料,企業可以精確找出未標記的資料,並使用寫回表格將相關資訊寫回應用程式,自動修正標記政策不符問題,確保資料的一致性與完整性。
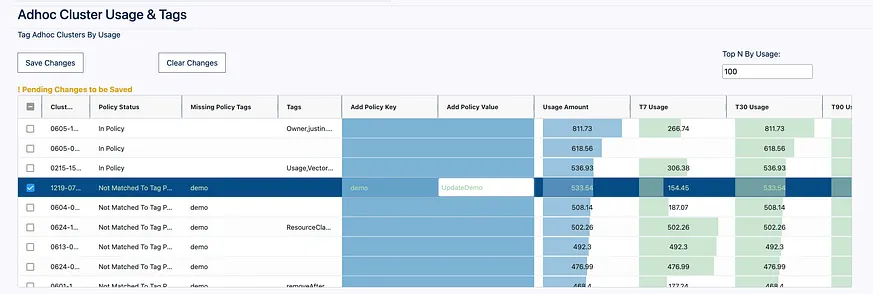
直接在我們的應用程式中,我們可以檢視按使用量排名的綜合用途、工作以及 SQL 資料倉庫使用情況。我們能夠檢視這些是否符合我們所選定的政策,並且可以利用 Dash 回寫功能在應用程式內直接新增標籤,使其符合規範。請記住,我們不希望編輯生產環境中的工作,我們實際上只需要進行分析,因此這些編輯會單獨儲存在我們自己的隔離 dash_observability_advisor 架構中。這使得我們能夠按使用量對計算資源進行排序,並快速且輕鬆地修正標籤,而不需讓終端使用者撰寫任何程式碼!
現在讓我們來看看當我們固定一些叢集並新增標籤後會發生什麼:
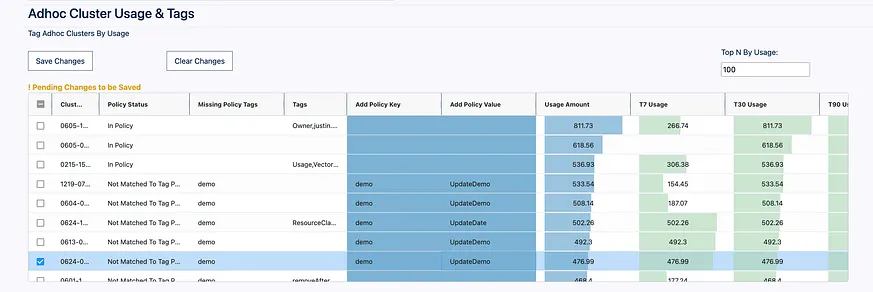
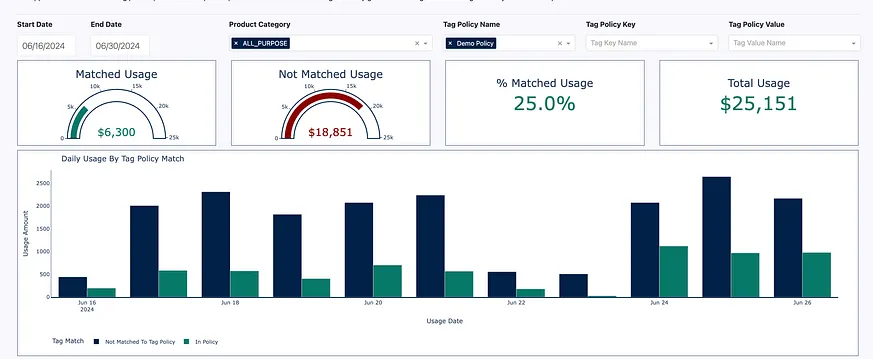
我們現在已經達到 25% 的遵循率,所以我們即將了解我們的使用情況,並且有一個簡單的框架來管理未來可能出現的偏差使用!進行這種合規性分析其實相當繁瑣,需要在背景執行複雜的 SQL,因此構建一個應用介面來圍繞這些分析工作流程是至關重要的,以使它們更易於訪問。為了展示生成這些視覺效果的一個 SQL 語句範例,以下是應用程式動態生成以建立這些遵循視覺效果的語句:
WITH filtered_usage AS ( SELECT * FROM clean_usage -- Query Filters WHERE usage_start_time >= '2024-06-16' :: timestamp AND usage_start_time <= '2024-06-30' :: timestamp AND billing_origin_product IN ('ALL_PURPOSE') ), active_tags AS ( SELECT *, 1 AS IsPolicyTag FROM app_tag_policies WHERE 1 = 1 AND tag_policy_name IN ('Demo Policy') ), combined_cluster_tags AS ( SELECT DISTINCT compute_asset_id, billing_origin_product, TagKey, TagValue, 1 AS IsUsageTag FROM ( SELECT COALESCE( clean_job_or_pipeline_id, clean_warehouse_id, clean_cluster_id ) AS compute_asset_id, billing_origin_product, clean_tags FROM filtered_usage ) LATERAL VIEW EXPLODE(clean_tags) AS TagKey, TagValue WHERE compute_asset_id IS NOT NULL UNION SELECT compute_asset_id AS compute_asset_id, compute_asset_type AS billing_origin_product, tag_key AS TagKey, tag_value AS TagValue, 1 AS IsUsageTag FROM app_compute_tags ), tag_potential_matches AS ( SELECT user_tags.compute_asset_id, user_tags.billing_origin_product, ( SELECT COUNT(0) FROM active_tags ) AS TotalPolicyTags, SUM(COALESCE(IsPolicyTag, 0)) AS NumberOfMatchedKeys, COUNT(DISTINCT tag_value) AS NumberOfMatchedValues, CASE WHEN NumberOfMatchedKeys >= TotalPolicyTags THEN 'In Policy' ELSE 'Not Matched To Tag Policy' END AS IsTaggingMatch, collect_set( CASE WHEN COALESCE(IsPolicyTag, 0) > 0 THEN CONCAT(TagKey, COALESCE(CONCAT(': ', TagValue), '')) END ) AS TagCombos, --TagCombo from tag policies collect_set( CASE WHEN IsPolicyTag = 1 THEN TagKey END ) AS MatchingTagKeys, collect_set( CASE WHEN IsPolicyTag = 1 THEN TagValue END ) AS MatchingTagValues, collect_set( CONCAT(TagKey, COALESCE(CONCAT(': ', TagValue), '')) ) AS updated_tags FROM combined_cluster_tags AS user_tags LEFT JOIN ( SELECT *, CONCAT(tag_key, COALESCE(CONCAT(': ', tag_value), '')) AS TagCombo FROM active_tags ) p ON user_tags.TagKey = p.tag_key AND ( p.tag_value IS NULL OR p.tag_value = "" OR user_tags.TagValue = p.tag_value ) GROUP BY user_tags.compute_asset_id, user_tags.billing_origin_product ), unmatched_policies AS ( SELECT a.compute_asset_id, p.tag_key AS UnmatchedPolicyKey FROM ( SELECT DISTINCT compute_asset_id, billing_origin_product FROM combined_cluster_tags ) a CROSS JOIN active_tags p LEFT JOIN combined_cluster_tags u ON a.compute_asset_id = u.compute_asset_id AND p.tag_key = u.TagKey AND ( p.tag_value IS NULL OR p.tag_value = "" OR p.tag_value = u.TagValue ) WHERE u.TagKey IS NULL ), clean_tag_matches AS ( SELECT tpm.*, collect_set(up.UnmatchedPolicyKey) AS MissingPolicyKeys FROM tag_potential_matches tpm LEFT JOIN unmatched_policies up ON tpm.compute_asset_id = up.compute_asset_id GROUP BY tpm.compute_asset_id, tpm.billing_origin_product, tpm.TotalPolicyTags, tpm.NumberOfMatchedKeys, tpm.NumberOfMatchedValues, tpm.MatchingTagKeys, tpm.MatchingTagValues, tpm.IsTaggingMatch, tpm.TagCombos, tpm.updated_tags ), px_all AS ( SELECT DISTINCT sku_name, pricing.default AS unit_price, unit_price :: decimal(10, 3) AS sku_price FROM system.billing.list_prices QUALIFY ROW_NUMBER() OVER ( PARTITION BY sku_name ORDER BY price_start_time DESC ) = 1 ), final_parsed_query AS ( SELECT u.*, -- TO DO: Add Discounts Table Later ((1 - COALESCE(NULL, 0)) * sku_price) * usage_quantity AS Dollar_DBUs, -- Combine system tags with App tags -- Combine system tags with App tags u.clean_tags AS updated_tags, ( SELECT COUNT(0) FROM active_tags ) AS TotalPolicyTags, COALESCE(ct.MatchingTagKeys, array()) AS MatchingTagKeys, COALESCE( ct.MissingPolicyKeys, ( SELECT collect_set(tag_key) FROM active_tags ) ) AS MissingTagKeys, COALESCE(ct.NumberOfMatchedKeys, 0) AS NumberOfMatchedKeys, COALESCE(ct.MatchingTagValues, array()) AS MatchedTagValues, COALESCE(ct.MatchingTagKeys, array()) AS MatchedTagKeys, COALESCE(ct.IsTaggingMatch, 'Not Matched To Tag Policy') AS IsTaggingMatch, ct.TagCombos AS TagCombos FROM filtered_usage AS u INNER JOIN px_all AS px ON px.sku_name = u.sku_name --- Join up tags persisted from the app LEFT JOIN clean_tag_matches ct ON ( ct.compute_asset_id = u.clean_cluster_id AND u.billing_origin_product = ct.billing_origin_product ) OR ( ct.compute_asset_id = u.clean_job_or_pipeline_id AND u.billing_origin_product = ct.billing_origin_product ) OR ( ct.compute_asset_id = u.clean_warehouse_id AND u.billing_origin_product = ct.billing_origin_product ) ), filtered_result AS ( -- Final Query - Dynamic from Filters SELECT * FROM final_parsed_query AS f WHERE 1 = 1 ) -- TAG DATE AGG QUERY SELECT usage_date AS Usage_Date, SUM(Dollar_DBUs_List) AS `Usage Amount`, IsTaggingMatch AS `Tag Match` FROM filtered_result GROUP BY usage_date, IsTaggingMatch降低分析門檻並提升非技術人員的可及性
從流程的角度來看,這是一個非常基本的閱讀→分析→編輯→分析→報告的內部問題解決工作流程,但這款應用程式完全將所有複雜的分析隱藏在幕後,使最終使用者不必面對這些繁瑣的步驟。**專家見解:**這個應用程式不僅簡化了分析流程,還將複雜的分析工作隱藏在幕後,使非技術人員也能輕鬆使用。未來幾年,資料團隊將變得更有價值,因為他們能夠將此類分析工作擴充套件到技術能力較弱的使用者,並加快進度。這是資料產品的一個早期範例。儘管它不是最吸引人的使用案例,但實際上是我看到客戶面臨的最常見挑戰之一!現在我們已經掌握了一個基本案例,我們繼續探討第二個使用案例。這個使用案例主要是關於如何讓系統表中的複雜問題警示更加容易啟用。同樣地,我們將從一則使用者故事開始:
“作為一名業務使用者,我希望能夠輕鬆地在我的系統表資料中建立和管理針對細微且具體問題的警示,而無需進行大量 SQL 編碼及學習如何使用 API 來建立和安排警示。”**趨勢預測:**對複雜問題設定警示,將成為一個越來越普遍的挑戰。資料團隊必須專注於開發易於使用的工具,使業務使用者能夠在不具備編碼技能的情況下,設定和管理警示。
回到我們的架構設計,我們重點關注應用程式中的警報管理器部分:

AI賦能警示管理,視覺化資料編輯無痛上手
**最新趨勢:AI 輔助警示管理**在傳統警示管理中,使用者必須手動設定複雜的 SQL 查詢,並編寫程式碼以設定警示條件和訂閱。現在,我們的應用程式透過 AI_QUERY 和大語言模型 (LLM) 的結合,大幅簡化此流程,使用者只需輸入自然語言查詢,即可自動產生最佳化的 SQL 查詢、預設警示條件和訂閱組態。
我們的警示管理器將:
1. 在 Unity Catalog 中建立並註冊一個帶有預置提示(pre-prompts)的 SQL 函式,以便為應用程式利用 AI_QUERY。
2. 建立一個具有 Dash App 回撥函式(callbacks)的聊天視窗,使使用者能與模型互動,以生成所需的所有警示部分,例如 SQL 查詢、排程、訂閱者、警示條件等。
3. 利用帶有 Dash App 回撥函式的回寫表(writeback table)來註冊查詢、建立警示,以及基於 LLM 從使用者英語問題中生成的引數來建立執行該警示的 Databricks 任務。
4. 允許使用者在一個地方管理(編輯/移除/檢視)已儲存生成的警示。
**深入要點:視覺化資料編輯介面**
除了自動化功能外,我們的應用程式還提供視覺化資料編輯介面,使使用者可以輕鬆檢視、編輯和管理其生成的警示。透過拖放介面和直觀的控制項,使使用者可以輕鬆建立、修改和移除警示,無需撰寫任何程式碼。
這是我們應用程式的一些介面樣貌:
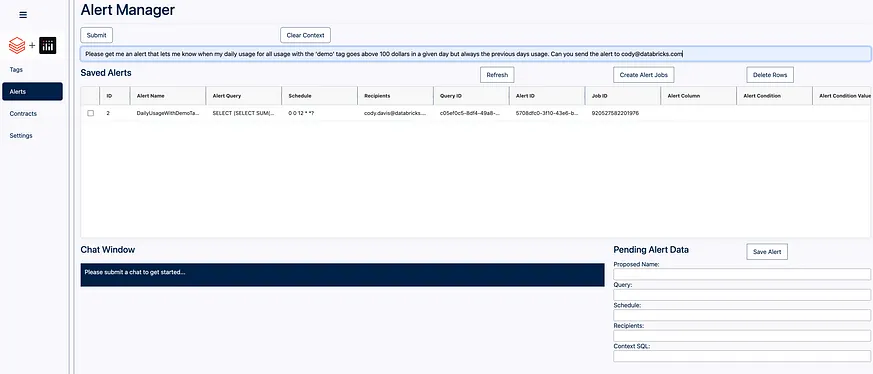
使用者友善的介面可設定警報通知
這是一個非常簡單的使用者介面(UI),它提供了一個提示輸入框、聊天視窗、一個編輯進行中警報的位置,以及一個可寫回(AGGrid)的表格,以儲存警報及其生成的所有後設資料(如 alertId、query id 和 job Id)。我們可以透過提示框提交一個問題:′請幫我設定一個警報,當我的日常使用量標記為 ′demo′ 的所有使用在某天超過 100 美元時通知我,但總是針對前一天的使用量。我希望該警報每天凌晨 3 點執行。能否將警報傳送到 cody@email.com′。在這個問題中,我們要求生成一個針對特定標籤日常使用量的警報。我們還要求應用每日 100 美元的門檻,並帶有24小時延遲的細微差別。我們也要求為此建立一個排程並將其傳送到特定的電子郵件地址。當我們提交這項請求後,我們會得到以下結果:

我們可以繼續聊天並讓 LLM 編輯它建立的待處理警報,或者我們可以直接在文字框中編輯這些值。這使得根據輸出結果靈活調整變得容易。我們來和 DBRX 多聊聊以細化我們的需求。我們將提交另一個問題:「你能把時間表改成每天晚上6點嗎?還有,你也能傳送給我的老闆 my_manager@email.com 嗎?」我們新增提示並點選提交,得到以下結果:
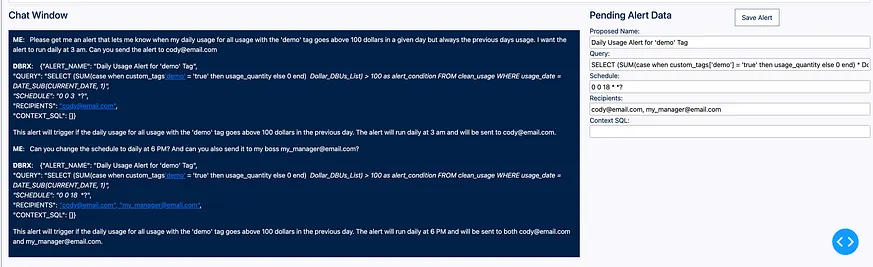
這是一個非常強大的迭代功能!現在當我們覺得已經完成時,可以點選「Save Alert」按鈕。這將利用 databricks-sdk 來解析從 DBX 獲得的輸出,並建立所有所需的正式查詢、警報和作業。它會自動將所有這些資訊儲存到我們的回寫表中,如下所示:
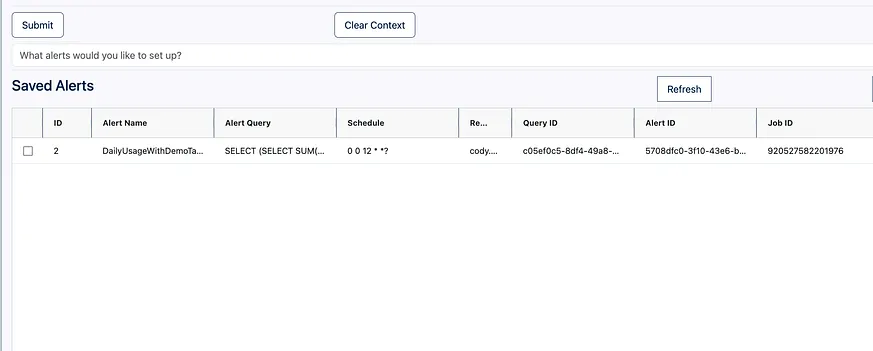
如果我們在工作區中搜尋輸出作業的 ID,我們可以看到它建立了我們的作業!

這是一種基本但非常強大的工作流程,展示了在 Databricks 上構建資料應用程式的可能性,並且再次透過在 Databricks SQL 上的 Dash App 回撥功能得以實現。例如,以下是填充和管理聊天反饋迴圈的回撥:
##### LLM Alert Manager ##### @app.callback( [Output('chat-history', 'data'), Output('chat-output-window', 'children'), Output('chat-input-box', 'value'), Output('in-progress-alert', 'data')], [Input('chat-submit-btn', 'n_clicks'), Input('clear-context-btn', 'n_clicks')], [State('chat-input-box', 'value'), State('chat-history', 'data')], prevent_initial_call=True ) def submit_chat(chat_submit_n_clicks, clear_context_n_clicks, input_value, history): ctx = dash.callback_context if not ctx.triggered: return dash.no_update, dash.no_update, dash.no_update, dash.no_update button_id = ctx.triggered[0]['prop_id'].split('.')[0] if button_id == 'clear-context-btn': # Clear the chat history return {'messages': []}, "Chat history cleared.", "", {'data': {'alert': {}}} if button_id == 'chat-submit-btn' and input_value: new_history = history['messages'][-4:] # keep only the last 4 messages for rolling basis new_input = """**ME**: """+ input_value new_history.append(new_input) response_message = "" # Formulate the input for AI Query ### each new prompt/response combo chat_updated_input = '\n\n'.join(new_history) query = text("SELECT result FROM generate_alert_info_from_prompt(:input_prompt)") try: # Assuming system_query_manager.get_engine() is predefined and correct engine = system_query_manager.get_engine() with engine.connect() as conn: result = conn.execute(query, parameters={'input_prompt': chat_updated_input}) row = result.fetchone() new_output = row[0] if row: response_message = """**DBRX**: """ + new_output else: response_message = """**DBRX**: """ + "No response generated." new_history.append(response_message) except Exception as e: response_message = """**DBRX**: """ + f"ERROR getting alert data: {str(e)}" new_history.append(response_message) #print(f"CONTEXT CHAIN: \n{new_history}") #print(f"CURRENT OUTPUT: \n {new_output}") parsed_updated_output = parse_query_result_json_from_string(new_output) print(parsed_updated_output) #print(parsed_updated_output) return {'messages': new_history}, '\n\n'.join(new_history), "", {'alert': parsed_updated_output} return dash.no_update, dash.no_update, dash.no_update, dash.no_update 在這張截圖中,我們可以看到它呼叫了 `generate_alert_info_from_prompt` 這個 SQL 函式來生成回應。這是一個應用程式內建並部署於 Unity Catalog 的 SQL 函式。我們可以前往 `dash_observability_advisor` 架構,並檢視其下的 ′Functions′。
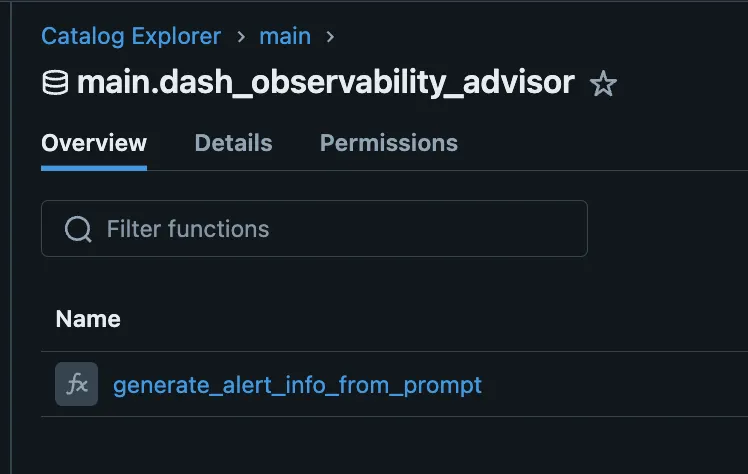
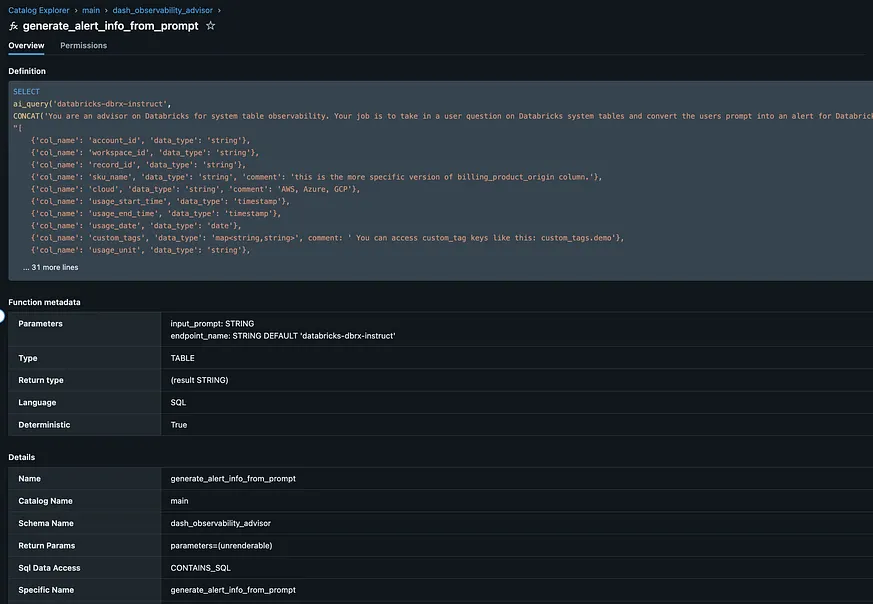
我們可以看到,將這個函式註冊到 Unity Catalog 中,使我們能夠封裝複雜的提示工程(prompt engineering),從而讓應用程式和最終使用者可以立即加以利用。
藉由低程式碼工具賦能非技術人員:打造資料應用程式的力量
或許最重要的是,我們可以透過我們的應用程式原生地使用 Unity Catalog 來管理所有這些提示和上下文,此外還包括資料表、原始資料、具像化檢視、模型以及任何函式(AI 和常規)。這兩個應用程式範例只是 Databricks 使用者在 Delta Uniform 開放資料層、Unity Catalog 開放治理層和 Plotly Dash 開放前端框架上能夠構建的資料產品的開始。在 Databricks 平台上,我們使用 Python + SQL 建立了一些強大的工作流程,使非技術使用者也能掌握主控權。藉由整合 Plotly Dash 等低程式碼工具,使用者能以直覺化的方式建立資料應用程式介面,無須深入了解程式碼,從而賦能非技術人員自主建構與維護資料應用程式。這種生產型資料應用程式概念將隨著嵌入 AI 的引入變得更容易運用,而且會使資料團隊更加具有價值。
我們希望你喜歡這篇部落格!如果你對系列文章中關於低層級實作最佳實踐和步驟建立這些應用感興趣,請隨時聯絡我們或留言!
參考來源
Data Visualization資料視覺化- Python -Plotly進階視覺化— Dash教學(一)
Dash是什麼? · 簡單來說,它就是可以讓我們在網頁上呈現我們的數據視覺化結果,並搭配著網頁前端的功能,使其更具互動性與美觀 · 它是一個flask輕量級的web ...
來源: Medium【Python】相關文章與討論
png) **Plotly**是一個開源資料視覺化函式庫,支援多種圖表類型和互動功能。它可用於多種程式語言,包括Python、R 和JavaScript。 Plotly.js 是該函式庫的JavaScript ...
來源: CodeLove 愛寫扣論壇wuwenjie1992/StarryDivineSky: 精选了5K+项目,包括机器学习、深度 ...
精选了5K+项目,包括机器学习、深度学习、NLP、GNN、推荐系统、生物医药、机器视觉、前后端开发等内容。Selected more than 5000 projects, including machine ...
來源: GitHub【附完整程式碼教學】教你一步一步用Python 打造數據實驗室,輕鬆預測 ...
相對於使用一些更成熟的Python數據可視化庫,例如Matplotlib ,用Plotly 是一個不那麼傳統的選擇,但我認為Plotly是一個不錯的選擇,因為它可以調用D3.js ...
來源: 報橘README.md · master · git pp / 最优质的资源-Awesome Projects
利用多种优化技术(深度学习编译器、量化、稀疏性、蒸馏等),以确定在特定硬件上执行AI 模型的最佳方式。可以在不损失性能的情况下将您的模型加速2 到10 ...
來源: GitPP【models】相關文章與討論
png) MindsDB 是一個利用企業資料客製化人工智慧的平台。 透過MindsDB,您可以利用資料庫、向量儲存或應用程式中的資料即時部署、服務和微調模型,以建立人工智慧驅動 ...
來源: CodeLove 愛寫扣論壇用于C++和Python专业机器人开发的工具,涉及ROS
用于C++和Python专业机器人开发的工具,涉及ROS、自动驾驶和航空航天。Tooling for professional robotic development in C++ and Python with a touch of ROS, ...
來源: GitHub程式設計 - MEPO Forum
另外這款工具除了可以做視覺化報表,同時也提供大屏的服務。通過佈局、色彩、綁定資料等環節完成大屏戰情室的製作,擁有很多自助開發的視覺化外掛程式庫。 因為後端通常 ...
來源: RSSing.com
 全部
全部 資訊科技
資訊科技
相關討論